spark ecosystem-Spark生态系统:解锁大数据魔法
创始人
2024-12-16 04:46:36
0次
Spark生态系统是一个庞大且多样化的开源大数据处理框架,包括了SparkCore、SparkSQL、SparkStreaming、MLlib、GraphX等多个组件。SparkCore是整个生态系统的核心,提供了基本的数据处理功能和API。SparkSQL则支持结构化数据处理,让用户可以通过SQL语句查询数据。而SparkStreaming则是用于实时流处理的组件,能够处理实时数据流并进行计算分析。
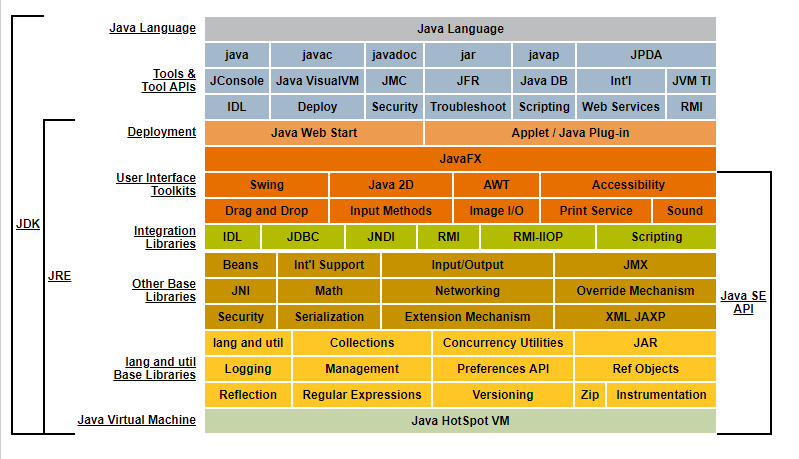
除了上述核心组件外,MLlib是Spark生态系统中的机器学习库,提供了各种常见的机器学习算法实现。GraphX则是图计算框架,适用于处理图结构数据。此外,还有许多其他扩展组件和工具,如SparkR用于R语言编程、SparkML用于机器学习管道等。

在实际应用中,Spark生态系统可以广泛应用于大规模数据处理、机器学习模型训练、实时流处理等场景。通过使用Spark生态系统,用户可以高效地处理海量数据,并且能够快速构建复杂的数据处理流程和机器学习模型。
总的来说,Spark生态系统提供了丰富的功能和灵活性,使得用户能够更加便捷地进行大数据处理和分析工作。随着技术的不断发展和完善,相信Spark生态系统将在大数据领域发挥越来越重要的作用。
imtoken官网版下载:https://cjge-manuscriptcentral.com/software/66002.html
相关内容
热门资讯
安卓换鸿蒙系统会卡吗,体验流畅...
最近手机圈可是热闹非凡呢!不少安卓用户都在议论纷纷,说鸿蒙系统要来啦!那么,安卓手机换上鸿蒙系统后,...
安卓系统拦截短信在哪,安卓系统...
你是不是也遇到了这种情况:手机里突然冒出了很多垃圾短信,烦不胜烦?别急,今天就来教你怎么在安卓系统里...
安卓系统要维护多久,安卓系统维...
你有没有想过,你的安卓手机里那个陪伴你度过了无数日夜的安卓系统,它究竟要陪伴你多久呢?这个问题,估计...
安装了Anaconda之后找不...
在安装Anaconda后,如果找不到Jupyter Notebook,可以尝试以下解决方法:检查环境...
app安卓系统登录不了,解锁登...
最近是不是你也遇到了这样的烦恼:手机里那个心爱的APP,突然就登录不上了?别急,让我来帮你一步步排查...
安卓系统如何卸载app,轻松掌...
手机里的App越来越多,是不是感觉内存不够用了?别急,今天就来教你怎么轻松卸载安卓系统里的App,让...
windows官网系统多少钱
Windows官网系统价格一览:了解正版Windows的购买成本Windows 11官方价格解析微软...
怎么复制照片安卓系统,操作步骤...
亲爱的手机控们,是不是有时候想把自己的手机照片分享给朋友,或者备份到电脑上呢?别急,今天就来教你怎么...
安卓系统应用怎么重装,安卓应用...
手机里的安卓应用突然罢工了,是不是让你头疼不已?别急,今天就来手把手教你如何重装安卓系统应用,让你的...
iwatch怎么连接安卓系统,...
你有没有想过,那款时尚又实用的iWatch,竟然只能和iPhone好上好?别急,今天就来给你揭秘,怎...